This page contains the MPST corpus, a collection of plot synopses and tags of 14,828 movies.
Contributors
Abstract
Social tagging of movies covers a wide range of heterogeneous information about movies, like the genre, plot structure, visual experiences, soundtracks, metadata, and emotional experiences from watching a movie. Being able to automatically generate or predict tags for movies can help recommendation engines to improve retrieval of similar movies, and also help viewers to know what to expect from a movie in advance. We hypothesize that written plot synopses of movies are valuable to infer relevant tags, and therefore we set out to the task of collecting a corpus of movie plot synopses and tags. We describe a methodology that helped us to build a fine-grained set of around 70 tags representing heterogeneous characteristics of movie plots and these tags’ multi-label associations with some 14K movie plot synopses. We investigate how tags correlate with movies and emotion flows of different types of movies. We plan to use this corpus to explore the feasibility of inferring tags from synopses, but we expect the corpus to be useful in other tasks where analysis of narratives is relevant.
Partially Funded By :
National Science Foundation under grant number 1462141
Overview of the Dataset
-
Fine-grained Tag Clusters
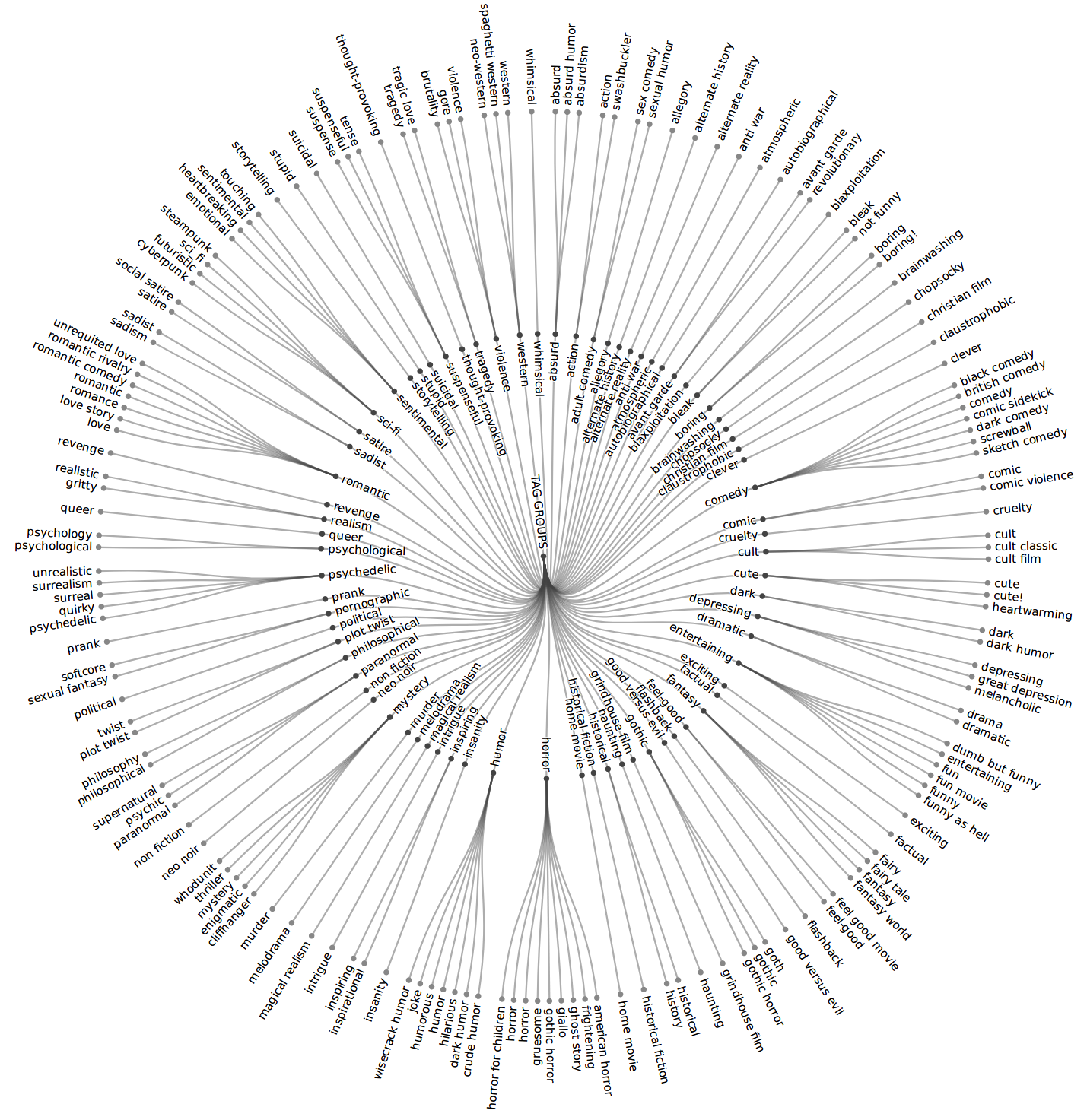
-
Number of Movies for Each Tag
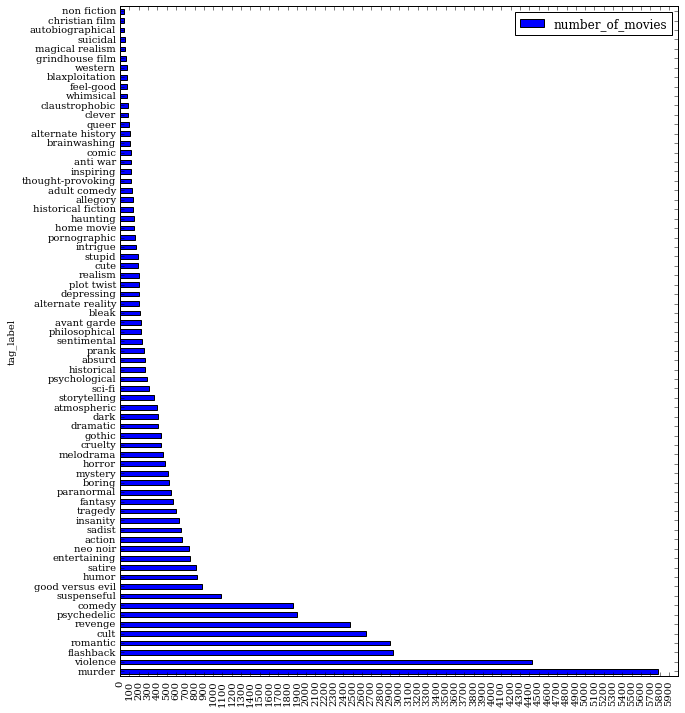
Read the paper Here
Download the Corpus
* Please fill out the form to download the dataset. An URL will appear below the Download button.
* The dataset is licensed under the GNU GENERAL PUBLIC LICENSE.
* MPST v2 now contains reviews of the movies. See details here.
If you face trouble downloading the data, please contact the first author skar3 AT uh DOT edu.
Cite the paper using
@InProceedings{KAR18.332,
author = {Sudipta Kar and Suraj Maharjan and A. Pastor López-Monroy and Thamar Solorio},
title = {{MPST}: A Corpus of Movie Plot Synopses with Tags},
booktitle = {Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018)},
year = {2018},
month = {May},
date = {7-12},
location = {Miyazaki, Japan},
editor = {Nicoletta Calzolari (Conference chair) and Khalid Choukri and Christopher Cieri and Thierry Declerck and Sara Goggi and Koiti Hasida and Hitoshi Isahara and Bente Maegaard and Joseph Mariani and Hélène Mazo and Asuncion Moreno and Jan Odijk and Stelios Piperidis and Takenobu Tokunaga},
publisher = {European Language Resources Association (ELRA)},
address = {Paris, France},
isbn = {979-10-95546-00-9},
language = {english}
}
For any query, please contact the first author skar3 AT uh DOT edu.